














 |
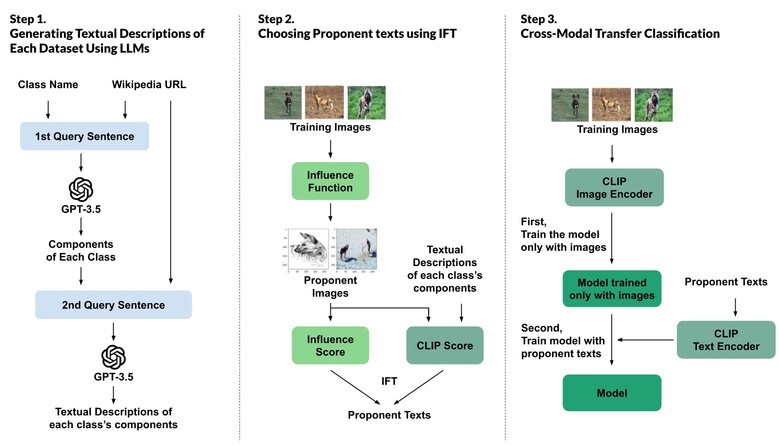
| ▲ 대형언어모델(LLM)을 활용한 데이터 설명문 생성 및 선별·학습 과정 개요 (사진= UNIST 제공) |
[mdtoday=박성하 기자] 인공지능(AI), 특히 딥러닝 모델은 높은 성능에도 불구하고 판단 근거를 설명하기 어려운 ‘블랙박스(Black-box)’로 불려왔다. 이런 한계를 극복하기 위해 AI 모델이 아닌 학습 데이터 자체를 사람의 언어로 설명하는 새로운 접근법이 제시됐다.
울산과학기술원(UNIST) 인공지능대학원 김태환 교수 연구팀은 대형언어모델(LLM)을 활용해 AI 학습 데이터를 자연어로 변환·분석함으로써, 딥러닝 모델의 의사결정 과정을 설명하는 새로운 학습 방법론을 제안했다고 28일 밝혔다.
그동안 설명 가능한 인공지능(XAI) 연구는 학습이 끝난 모델의 내부 연산 구조나 예측 결과를 사후적으로 분석하는 방식에 집중해 왔다. 그러나 이러한 접근은 모델이 학습 과정에서 어떤 데이터 특징을 실제로 참고했는지를 직관적으로 설명하는 데 한계가 있었다.
연구팀은 이에 착안해 AI 모델이 아니라, 모델을 구성하는 근본 요소인 ‘학습 데이터’에 주목했다. 이미지 데이터에 대해 LLM이 생성한 설명문을 활용해, AI가 어떤 특징을 근거로 판단했는지를 언어적으로 드러내는 방식이다.
연구팀은 먼저 챗GPT와 같은 LLM을 활용해 이미지 속 사물의 특징을 여러 문장으로 설명하도록 했다. 이 과정에서 환각 현상을 줄이기 위해 인터넷 백과사전 등 외부 지식도 함께 참고하도록 설계했다.
다만 LLM이 생성한 모든 설명문이 모델 학습에 유의미한 것은 아니다. 연구팀은 실제로 모델의 성능 향상에 기여한 설명문을 가려내기 위해 텍스트 영향력 점수(IFT·Influence scores For Texts)라는 정량적 지표를 고안했다.
IFT는 특정 설명문을 학습 데이터에서 제외했을 때 모델의 예측 오차 변화로 계산한 ‘영향력 점수’와, 텍스트 설명이 이미지의 시각 정보와 얼마나 의미적으로 일치하는지를 나타내는 CLIP 점수를 결합해 산출된다.
예를 들어 조류 분류 모델에서 ‘부리의 형태’나 ‘깃털의 무늬’를 묘사한 설명문이 배경 색상 설명보다 높은 IFT 점수를 기록했다면, 해당 모델은 실제로 부리와 깃털의 특징을 학습해 대상을 식별했다고 해석할 수 있다.
연구팀은 영향력이 높은 설명문이 실제 모델 성능 향상에도 기여하는지를 검증하기 위해 별도의 벤치마크 실험을 수행했다. 그 결과, 영향력이 큰 설명문을 함께 학습시킨 경우 기존 방식보다 더 안정적으로 높은 분류 성능을 보였다.
또한 크로스 모달 전이 분류와 제로샷(Zero-shot) 학습 실험에서도 텍스트와 이미지 간 의미 정합도가 향상되며 성능 개선 효과가 확인됐다. 이는 모델이 학습 과정에서 실제로 참고한 설명이 성능에도 실질적인 영향을 미친다는 점을 입증한 결과다.
김태환 교수는 “AI가 스스로 자신이 학습하는 데이터를 설명하는 방식은 딥러닝의 복잡한 의사결정 과정을 본질적으로 드러낼 수 있다”며 “향후 블랙박스 AI 시스템을 투명하게 이해하는 기반이 될 것”이라고 말했다.
메디컬투데이 박성하 기자([email protected])


[저작권자ⓒ 메디컬투데이. 무단전재-재배포 금지]




























